
LLM Consensus Matches or Outperforms the Best AI Models in Expert Evaluation Without Performance Degradation
 BIS warns 'pressure points' putting global economy at risk
BIS warns 'pressure points' putting global economy at risk

 Ntamack aims to bring Toulouse Top 14 win 'energy' to Nations Championship campaign
Ntamack aims to bring Toulouse Top 14 win 'energy' to Nations Championship campaign

 'High-strung' camels race in Australian outback
'High-strung' camels race in Australian outback

 Algeria and Austria reach World Cup knockouts after 3-3 thriller
Algeria and Austria reach World Cup knockouts after 3-3 thriller

 DR Congo advance but Iran out as wild World Cup group stage wraps
DR Congo advance but Iran out as wild World Cup group stage wraps

 Austria and Algeria reach World Cup knockouts after 3-3 thriller
Austria and Algeria reach World Cup knockouts after 3-3 thriller

 Where are they? Dogs disappear before South Korea meat ban
Where are they? Dogs disappear before South Korea meat ban

 China's bull wrestlers fight to keep tradition alive
China's bull wrestlers fight to keep tradition alive

 England top group to set up DR Congo World Cup clash, Portugal held
England top group to set up DR Congo World Cup clash, Portugal held

 England moving on at World Cup but questions linger
England moving on at World Cup but questions linger

 Venezuela quakes kill 1,400 as time running out to find survivors
Venezuela quakes kill 1,400 as time running out to find survivors

 Australia World Cup goalkeeper Patrick Beach has beach named after him
Australia World Cup goalkeeper Patrick Beach has beach named after him

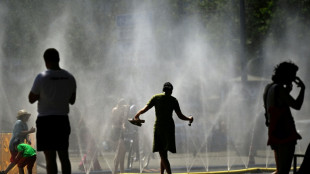 Take brutally hot weather seriously, heatstroke survivor warns
Take brutally hot weather seriously, heatstroke survivor warns

 Australia boosts shark-spotting drone coverage at Sydney beaches
Australia boosts shark-spotting drone coverage at Sydney beaches

 Scotland boss Clarke resigns after World Cup exit confirmed
Scotland boss Clarke resigns after World Cup exit confirmed

 Kane, Bellingham on target as England win World Cup group
Kane, Bellingham on target as England win World Cup group

 Croatia battle past Ghana to sew up World Cup Last 32 spot
Croatia battle past Ghana to sew up World Cup Last 32 spot

 US, Iran clash, putting fragile deal under growing strain
US, Iran clash, putting fragile deal under growing strain

 Ryu takes one-shot lead over Henderson at Women's PGA Championship
Ryu takes one-shot lead over Henderson at Women's PGA Championship

 Jangoo and Chase put West Indies in control against Sri Lanka
Jangoo and Chase put West Indies in control against Sri Lanka

 World Cup star Gakpo requests privacy after death of unborn son
World Cup star Gakpo requests privacy after death of unborn son

 Aid planes landing at partially reopened Venezuela airport after quakes
Aid planes landing at partially reopened Venezuela airport after quakes

 Spain's Williams hits out at Uruguay over World Cup injury
Spain's Williams hits out at Uruguay over World Cup injury

 World's largest particle smasher halts for upgrade to boost hunt for dark matter
World's largest particle smasher halts for upgrade to boost hunt for dark matter

 Ex-Olympic medallist Canderloro elected French Ice Sports chief
Ex-Olympic medallist Canderloro elected French Ice Sports chief

A multi-model consensus system matches or outperforms GPT-5.4, Claude Opus 4.6 and Gemini 3.1 Pro across 100 expert-level questions infinance, law, medicine and technology, with no performance degradation.
SHERIDAN, WY / ACCESS Newswire / April 2, 2026 / LLM Consensus has released the results of its Expert-Domain Evaluation Benchmark v1.0, an independent study analyzing the performance of its multi-model consensus technology across 100 high-complexity questions in areas such as financial regulation, law, clinical medicine and technical architecture.
According to the results, the system matches or outperforms the best individual AI model across all evaluated questions, achieving measurable improvement in 44.9% of cases and with no instances of performance loss.
Key findings
In nearly half of the questions (45%), responses generated by the consensus system clearly outperformed those of the best individual model. The system was able to identify regulatory details that other models missed, resolve contradictions across sources, and deliver more complete answers.
In the remaining 55%, performance matched that of the best available model, ensuring a consistent baseline of quality without requiring users to choose between different models.
Additionally, in none of the 100 questions analyzed did the system produce a worse result than an individual model.
Performance by domain
The analysis focused on complex questions typical of regulated industries:
Clinical medicine (59% improvement): stronger performance in complex drug interactions, comorbidities, and application of clinical guidelines.
Financial regulation (50% improvement): advantages in scenarios combining multiple European regulatory frameworks such as DORA, PSD2, GDPR, and NIS2.
Legal analysis (44% improvement): greater precision in multi-jurisdictional and cross-regulatory compliance questions.
Technical architecture (30% improvement, 70% match): consistent results in system design decisions under regulatory and technical constraints.
Why it matters
The use of artificial intelligence in regulated industries continues to grow, yet no single model consistently excels across all domains. A system may perform well in financial regulation but fall short in clinical medicine, or vice versa.
LLM Consensus addresses this challenge by combining multiple leading models into a single response. It integrates technologies from OpenAI, Anthropic, Google, Mistral, and Meta, applying a synthesis process with cross-verification that leverages each model's strengths while reducing their weaknesses.
"Reliability is the core value proposition," the company said. "Users no longer have to decide which model to use. They get a single answer that consistently matches or outperforms the best available model for each case."
Evaluation methodology
The benchmark was specifically designed to assess tasks that require combining multiple sources of knowledge. Each question was evaluated by three independent reviewers from different AI providers, who scored responses blindly based on accuracy and quality.
Responses - from both the consensus system and individual models - were presented anonymously and in random order. Cases where sufficient agreement was not reached were classified as inconclusive and excluded from the final results.
The full dataset has been published to enable independent verification.
About LLM Consensus
LLM Consensus is an AI orchestration API that combines multiple advanced models into a single optimized response using patent-pending consensus technology.
The solution is available via REST API with different operating modes and is designed for developers and organizations in regulated sectors such as finance, healthcare, legal, and technology.
Press contact
Francisco Javier Nunez
Email: [email protected]
Web: llmconsensus.io
Patent pending: US 19/215,933 | EU EP25176020.3
This press release contains forward-looking statements based on current benchmark results. The evaluation was conducted using specific model versions as of March 2026; performance may vary with model updates. LLM Consensus is a system benchmark evaluating multi-model orchestration on expert synthesis tasks and should not be interpreted as a general-purpose comparison of individual AI models.
SOURCE: LLM Consensus
View the original press release on ACCESS Newswire
T.Sanchez--AT

